Category: Feedback request
Posts
New Working Draft of Requirements for Japanese Text Layout
A new version of Requirements for Japanese Text Layout has just been published as a Working Draft.
The plan is to replace the current W3C Working Group Note with the content of this new Working Draft after a period of review.
This document describes requirements for general Japanese layout realized with technologies such as CSS, SVG and XSL-FO. It is also being used by developers of other technologies, such as ebooks. The document builds on and further develops the Japanese standard for text layout, JIS X 4051.
This second version of the document contains a significant amount of additional information related to hanmen design, such as handling headings, placement of illustrations and tables, handling of notes and reference marks, etc.
Please take a look at the new version, which is available in English and Japanese, and send any comments to [email protected] (subscribe at the archive main page). Use “[JLReq]” in the subject line of your email, followed by a brief subject.
Send any comments before the end of December. We hope to publish the final version of the updated Working Group Note early in the New Year.
RSS feed links changed
The Internationalization Activity home page has recently been ported to WordPress. This means that the URIs for the various RSS feeds have changed. You can find the new links at the page W3C I18n news filters and RSS feeds.
The current URIs will continue to work for a short while, to support the transition, but you should change as soon as possible.
URIs for category filters have also changed, as have those for search key text within posts (useful for finding the history of a particular article or document). The latter have been converted to tags.
Feedback needed: Armenian list numbering
Since it is mentioned in the CSS 2.1 specification, Firefox, Opera and Safari (and maybe more) browsers allow you to number HTML lists using Armenian numerals.
The basic algorithm followed is described in the CSS3 Lists module.
You can see some tests and results.
Some questions have arisen about a couple of details relating to the approach specified in CSS3, and we would like to get clarity from people with appropriate knowledge of this subject. Please participate in the email discussion on [email protected] if you can help.
Please provide advice on the representation of 7000 and of numbers above 9,999.
In a recent email Simon Montagu expresses the questions as follows:
[This wikipedia link], which quotes no sources, corresponds to the implementation in Firefox and Opera (upper-case characters and only Ւ for 7000).
[This link] is an article from National Mathematics Magazine, Vol. 13, No. 8 (May, 1939). I don’t have access to download the full article, but the URI shows the first page, which includes a table showing lower-case characters and only ւ for 7000.
Furthermore, there are contradictions in http://www.w3.org/TR/css3-lists/ — the prose description of the algorithm says:
“This is a simple additive system defined for the range 1 to 99999999.
The digits are split into two groups of four (if there are less than eight digits, the least significant group is filled first). Within each group, appropriate digits are picked from the following list (at most one per column) and written in descending order by value (thousands first). Any characters in the most significant group are then combined with a circumflex accent, ◌̂ U+0302.”
This implies that the circumflex has the effect of multiplying by 10000, but the following example uses the circumflex to multiply by 1000:
“Example 1: Decimal 7482951 in lower-armenian is ու̂ն̂ձ̂սջծա U+0578 U+0582
U+0302 U+0576 U+0302 U+0571 U+0302 U+057D U+057B U+056E U+0561. ”
If the example is correct, the system will only be defined up to 9,999,999 and not 99,999,999. Digits from 1000 to 9000 would also have two possible representations: either ռ ս … or ա̂ բ̂ … and it isn’t clear whether one should be preferred or either may be used.
Request for feedback: Usefulness of ::first-letter in non-Latin scripts
The W3C i18n Working Group would like to hear from you if you have some knowledge/thoughts in this area. We would like to gather information about the usefulness, in general, of the ::first-letter pseudo-element in non-Latin scripts, and any particular issues or differences arising from the different characteristics of the scripts.Please send your comments to www-international @ w3.org (Archive and subscription: http://lists.w3.org/Archives/Public/www-international/)
The latest working draft of CSS3 Selectors proposes the ::first-letter pseudo-element.
See http://www.w3.org/TR/2005/WD-css3-selectors-20051215/#first-letter
The ::first-letter pseudo-element represents the first letter of the first line of a block, if it is not preceded by any other content (such as images or inline tables) on its line.
It allows that first letter to be styled individually, without markup. It may be used for “initial caps” and “drop caps”, which are common typographical effects in text in Latin script.
We commented to the CSS Working Group that they need to define ‘letter’ more carefully, and proposed that they specify that ‘letter’ equates to ‘default grapheme cluster’, as described in the Unicode Standard Annex #29.
See http://www.unicode.org/reports/tr29/#Grapheme_Cluster_Boundaries
(A rough and ready explanation of this is that base characters and any following combining characters are styled together. So
0065: e LATIN SMALL LETTER E + 0301: ́ COMBINING ACUTE ACCENT
would be handled as a single letter.)
We also suggested that implementors should then be encouraged to provide tailored algorithms on a per language basis to cope with anomolies, particularly such as may occur in non-Latin scripts.
Here are some initial questions:
[1] Are there scripts that would never use this approach?
[2] We mention ‘initial caps’ and ‘drop caps’ above. What other types of styling would be commonly applied in other scripts if this feature were available?
[3] What script features would cause difficulties, eg syllabic groupings (see the example of indic script example below), ligatures, cursive text (eg. Arabic, Urdu, etc.), and how would the script normally deal with them?
Please send your comments to www-international @ w3.org
Archive: http://lists.w3.org/Archives/Public/www-international/
————
What follows are some examples of questions that spring to mind.
SYLLABIC INDIC SCRIPTS
In the Hindi word स्थिति (‘sthiti’) the sequence of characters in the first syllable is as follows in memory:
0938: स DEVANAGARI LETTER SA
094D: ् DEVANAGARI SIGN VIRAMA
0925: थ DEVANAGARI LETTER THA
093F: ि DEVANAGARI VOWEL SIGN I
The displayed text, however, is 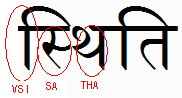
Note how the vowel sign appears to the left of the first character, not the third.
The default grapheme clusters here are, I believe, 0938+094D, then each of the following two characters.
Would Devanagari-based languages use special styling for initial syllables? If so, would they actually apply the styling to the vowel sign alone, or to the whole syllable?
LIGATURES
If a script styles the ‘first letter’, but that letter is part of a ligature (ie. a single glyph representing more than one underlying character), would it be ok to split the ligature, or should the other characters that compose the ligature also be styled?
CURSIVE SCRIPTS
Since Arabic and Mongolian letters in a word are normally joined, has first letter styling been used at all in these scripts?
CHINESE, JAPANESE, KOREAN
Do languages using these scripts do first letter styling?
RUSSIAN, GREEK, ARMENIAN, etc.
Is first letter styling common practise in these scripts too?
W3C®liability, trademark and permissive license rules apply.
Questions or comments? [email protected]