Errata Fixed in Unicode 6.0.0
This page contains the definitive listing of all errata of record
since the publication of The Unicode Standard, Version 5.2 and
considered resolved by the release of Unicode Version 6.0. These
errata are listed by date in the table below. For prior errata
resolved in Unicode 5.2 and earlier, see
Errata Fixed in Unicode 5.2.
For errata still pending subsequent to the release of Unicode
6.0.0, see the list of current
Updates and Errata.
| Date |
Summary |
|---|
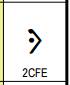
| 2015-May-29 |
The representative glyph for the character U+2CFE COPTIC FULL STOP was
incorrect in the code charts for Unicode 5.2. The original glyph could be considered a variant of U+2E16 DOTTED RIGHT-POINTING ANGLE, which was used in Greek and Coptic manuscripts. The glyph was changed to reflect one that is distinctively Coptic.
The figure below shows the incorrect glyph from the Unicode 5.2
code charts on the left, and the correct glyph used in Unicode 6.0 and
subsequent code charts on the right.
|
| 2010-Apr-2 |
On p. 258 of The Unicode Standard, Version 5.2,
in 8.4 Samaritan, SAMARITAN MARK DAGESH and SAMARITAN MARK
OCCLUSION are listed with incorrect code points. The correction is
as follows (the order of the two sentences is also reversed to
describe U+0818 first):Current text:
U+0818 SAMARITAN MARK DAGESH indicates consonant gemination.
U+0819 SAMARITAN MARK OCCLUSION "strengthens" the consonant, for
example changing /w/ to /b/.
Corrected text:
U+0818 SAMARITAN MARK OCCLUSION "strengthens" the consonant, for
example changing /w/ to /b/. U+0819 SAMARITAN MARK DAGESH
indicates consonant gemination.
|
| 2010-Mar-22 |
In R3 on p. 128 of The Unicode Standard, Version 5.2,
the words, ", immediately preceding a space
character" should be deleted. |
| 2009-Oct-14 |
In Version 5.2 (and Version 5.1) of
UAX #31, "Unicode Identifier and Pattern Syntax," there is an error in
Figure
2. Farsi Example with ZWNJ, where the code point numbers for Alef (U+0627)
and Meem (U+0645) are swapped. The correct values are:first row:
0646+0627+0645+0647+0627+06CC
second row:
0646+0627+0645+0647+200C+0627+06CC |
| 2009-Oct-1 |
In the Version 5.2 Unicode Character Database, there is one IRG source mapping missing in the data file Unihan_IRGSources.txt
(contained in Unihan.zip). The following entry should be
added:
U+2ADFF kIRG_HSource 87DC
|
| 2008-April-28 |
In the Version 5.1 Unicode Character Database, the test cases in the test data
file LineBreakTest.txt incorrectly indicate the presence of a break at the
beginning of each line (with "÷"). These should be corrected to indicate no
break at the beginning of each line (with "×"), to reflect the effect of LB2
"Never break at the start of text" from
UAX #14, "Unicode
Line Breaking Algorithm".
Correspondingly, the documentation in LineBreakTest.html should have the rule
0.2 corrected to read: "sot ×".
|
|
